The train-test split procedure is used to estimate the performance of machine learning algorithms when they are used to make predictions on data not used to train the model.
It is a fast and easy procedure to perform, the results of which allow you to compare the performance of machine learning algorithms for your predictive modeling problem. Although simple to use and interpret, there are times when the procedure should not be used, such as when you have a small dataset and situations where additional configuration is required, such as when it is used for classification and the dataset is not balanced.
In this tutorial, you will discover how to evaluate machine learning models using the train-test split.
After completing this tutorial, you will know:
- The train-test split procedure is appropriate when you have a very large dataset, a costly model to train, or require a good estimate of model performance quickly.
- How to use the scikit-learn machine learning library to perform the train-test split procedure.
- How to evaluate machine learning algorithms for classification and regression using the train-test split.
Let’s get started.

Train-Test Split for Evaluating Machine Learning Algorithms
Photo by Paul VanDerWerf, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Train-Test Split Evaluation
- When to Use the Train-Test Split
- How to Configure the Train-Test Split
- Train-Test Split Procedure in Scikit-Learn
- Repeatable Train-Test Splits
- Stratified Train-Test Splits
- Train-Test Split to Evaluate Machine Learning Models
- Train-Test Split for Classification
- Train-Test Split for Regression
Train-Test Split Evaluation
The train-test split is a technique for evaluating the performance of a machine learning algorithm.
It can be used for classification or regression problems and can be used for any supervised learning algorithm.
The procedure involves taking a dataset and dividing it into two subsets. The first subset is used to fit the model and is referred to as the training dataset. The second subset is not used to train the model; instead, the input element of the dataset is provided to the model, then predictions are made and compared to the expected values. This second dataset is referred to as the test dataset.
- Train Dataset: Used to fit the machine learning model.
- Test Dataset: Used to evaluate the fit machine learning model.
The objective is to estimate the performance of the machine learning model on new data: data not used to train the model.
This is how we expect to use the model in practice. Namely, to fit it on available data with known inputs and outputs, then make predictions on new examples in the future where we do not have the expected output or target values.
The train-test procedure is appropriate when there is a sufficiently large dataset available.
When to Use the Train-Test Split
The idea of “sufficiently large” is specific to each predictive modeling problem. It means that there is enough data to split the dataset into train and test datasets and each of the train and test datasets are suitable representations of the problem domain. This requires that the original dataset is also a suitable representation of the problem domain.
A suitable representation of the problem domain means that there are enough records to cover all common cases and most uncommon cases in the domain. This might mean combinations of input variables observed in practice. It might require thousands, hundreds of thousands, or millions of examples.
Conversely, the train-test procedure is not appropriate when the dataset available is small. The reason is that when the dataset is split into train and test sets, there will not be enough data in the training dataset for the model to learn an effective mapping of inputs to outputs. There will also not be enough data in the test set to effectively evaluate the model performance. The estimated performance could be overly optimistic (good) or overly pessimistic (bad).
If you have insufficient data, then a suitable alternate model evaluation procedure would be the k-fold cross-validation procedure.
In addition to dataset size, another reason to use the train-test split evaluation procedure is computational efficiency.
Some models are very costly to train, and in that case, repeated evaluation used in other procedures is intractable. An example might be deep neural network models. In this case, the train-test procedure is commonly used.
Alternately, a project may have an efficient model and a vast dataset, although may require an estimate of model performance quickly. Again, the train-test split procedure is approached in this situation.
Samples from the original training dataset are split into the two subsets using random selection. This is to ensure that the train and test datasets are representative of the original dataset.
How to Configure the Train-Test Split
The procedure has one main configuration parameter, which is the size of the train and test sets. This is most commonly expressed as a percentage between 0 and 1 for either the train or test datasets. For example, a training set with the size of 0.67 (67 percent) means that the remainder percentage 0.33 (33 percent) is assigned to the test set.
There is no optimal split percentage.
You must choose a split percentage that meets your project’s objectives with considerations that include:
- Computational cost in training the model.
- Computational cost in evaluating the model.
- Training set representativeness.
- Test set representativeness.
Nevertheless, common split percentages include:
- Train: 80%, Test: 20%
- Train: 67%, Test: 33%
- Train: 50%, Test: 50%
Now that we are familiar with the train-test split model evaluation procedure, let’s look at how we can use this procedure in Python.
Train-Test Split Procedure in Scikit-Learn
The scikit-learn Python machine learning library provides an implementation of the train-test split evaluation procedure via the train_test_split() function.
The function takes a loaded dataset as input and returns the dataset split into two subsets.
... # split into train test sets train, test = train_test_split(dataset, ...)
Ideally, you can split your original dataset into input (X) and output (y) columns, then call the function passing both arrays and have them split appropriately into train and test subsets.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, ...)
The size of the split can be specified via the “test_size” argument that takes a number of rows (integer) or a percentage (float) of the size of the dataset between 0 and 1.
The latter is the most common, with values used such as 0.33 where 33 percent of the dataset will be allocated to the test set and 67 percent will be allocated to the training set.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
We can demonstrate this using a synthetic classification dataset with 1,000 examples.
The complete example is listed below.
# split a dataset into train and test sets from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split # create dataset X, y = make_blobs(n_samples=1000) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
Running the example splits the dataset into train and test sets, then prints the size of the new dataset.
We can see that 670 examples (67 percent) were allocated to the training set and 330 examples (33 percent) were allocated to the test set, as we specified.
(670, 2) (330, 2) (670,) (330,)
Alternatively, the dataset can be split by specifying the “train_size” argument that can be either a number of rows (integer) or a percentage of the original dataset between 0 and 1, such as 0.67 for 67 percent.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67)
Repeatable Train-Test Splits
Another important consideration is that rows are assigned to the train and test sets randomly.
This is done to ensure that datasets are a representative sample (e.g. random sample) of the original dataset, which in turn, should be a representative sample of observations from the problem domain.
When comparing machine learning algorithms, it is desirable (perhaps required) that they are fit and evaluated on the same subsets of the dataset.
This can be achieved by fixing the seed for the pseudo-random number generator used when splitting the dataset. If you are new to pseudo-random number generators, see the tutorial:
This can be achieved by setting the “random_state” to an integer value. Any value will do; it is not a tunable hyperparameter.
... # split again, and we should see the same split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
The example below demonstrates this and shows that two separate splits of the data result in the same result.
# demonstrate that the train-test split procedure is repeatable from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split # create dataset X, y = make_blobs(n_samples=100) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # summarize first 5 rows print(X_train[:5, :]) # split again, and we should see the same split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # summarize first 5 rows print(X_train[:5, :])
Running the example splits the dataset and prints the first five rows of the training dataset.
The dataset is split again and the first five rows of the training dataset are printed showing identical values, confirming that when we fix the seed for the pseudorandom number generator, we get an identical split of the original dataset.
[[-2.54341511 4.98947608] [ 5.65996724 -8.50997751] [-2.5072835 10.06155749] [ 6.92679558 -5.91095498] [ 6.01313957 -7.7749444 ]] [[-2.54341511 4.98947608] [ 5.65996724 -8.50997751] [-2.5072835 10.06155749] [ 6.92679558 -5.91095498] [ 6.01313957 -7.7749444 ]]
Stratified Train-Test Splits
One final consideration is for classification problems only.
Some classification problems do not have a balanced number of examples for each class label. As such, it is desirable to split the dataset into train and test sets in a way that preserves the same proportions of examples in each class as observed in the original dataset.
This is called a stratified train-test split.
We can achieve this by setting the “stratify” argument to the y component of the original dataset. This will be used by the train_test_split() function to ensure that both the train and test sets have the proportion of examples in each class that is present in the provided “y” array.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1, stratify=y)
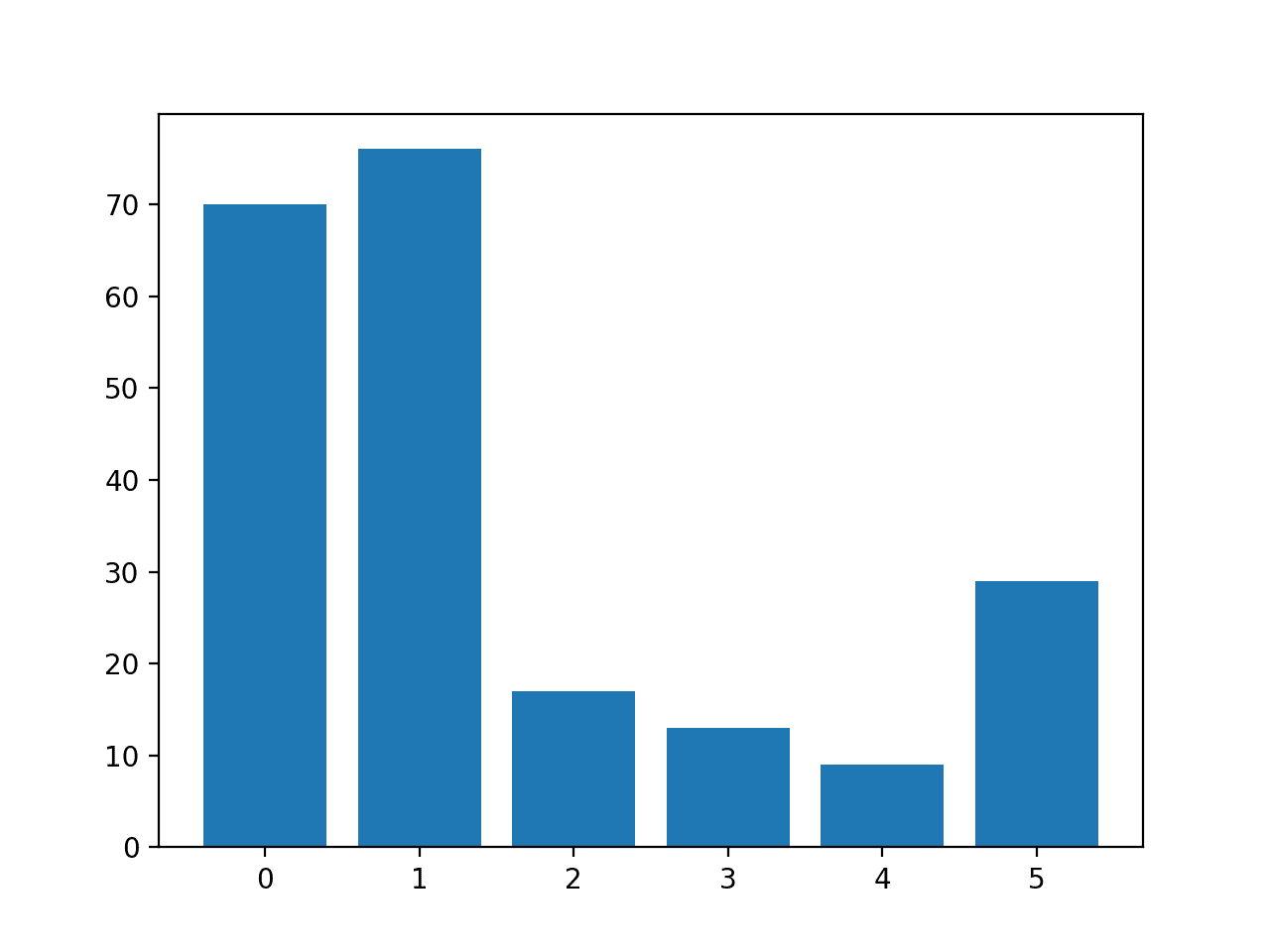
We can demonstrate this with an example of a classification dataset with 94 examples in one class and six examples in a second class.
First, we can split the dataset into train and test sets without the “stratify” argument. The complete example is listed below.
# split imbalanced dataset into train and test sets without stratification from collections import Counter from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split # create dataset X, y = make_classification(n_samples=100, weights=[0.94], flip_y=0, random_state=1) print(Counter(y)) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) print(Counter(y_train)) print(Counter(y_test))
Running the example first reports the composition of the dataset by class label, showing the expected 94 percent vs. 6 percent.
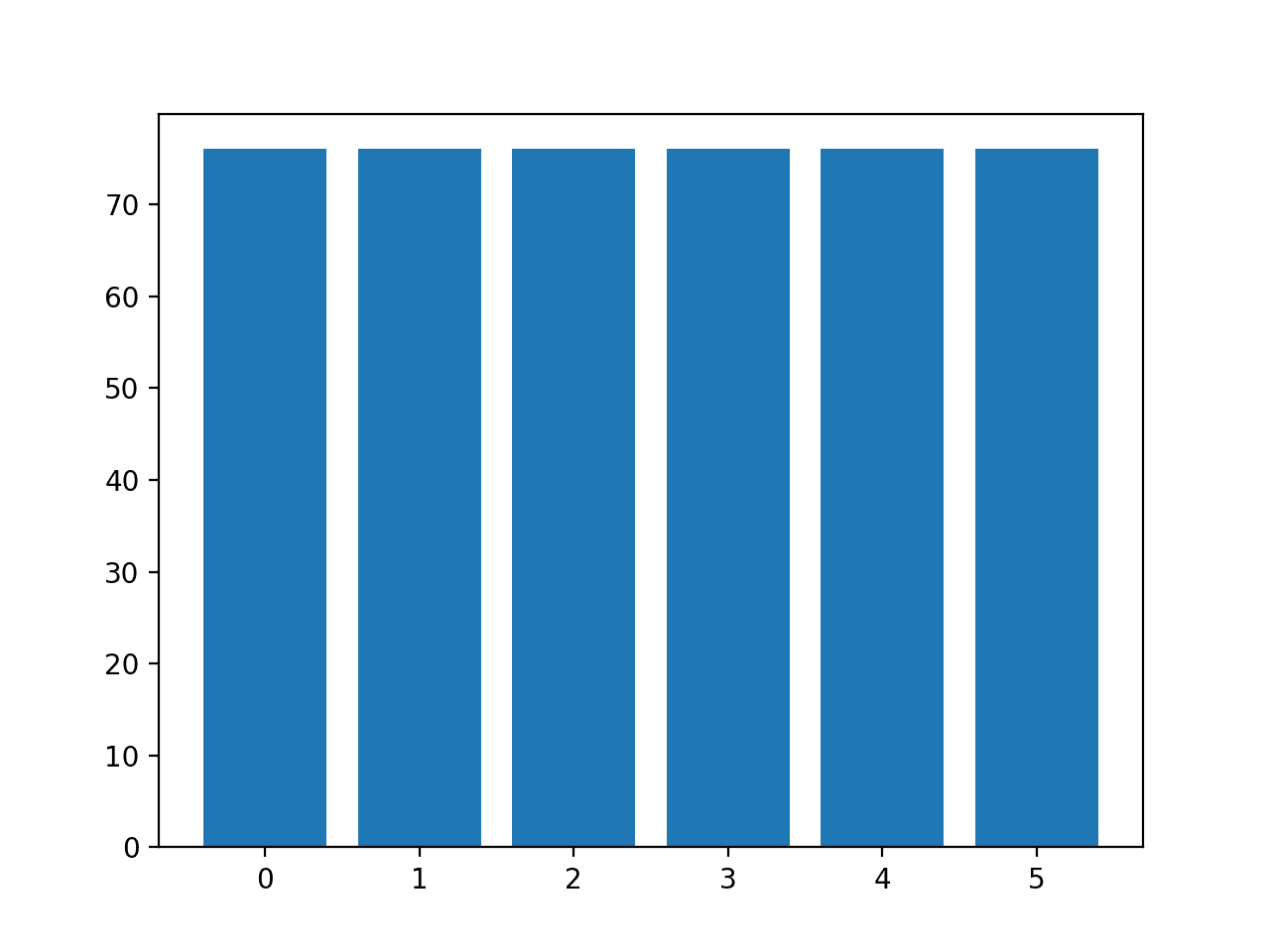
Then the dataset is split and the composition of the train and test sets is reported. We can see that the train set has 45/5 examples in the test set has 49/1 examples. The composition of the train and test sets differ, and this is not desirable.
Counter({0: 94, 1: 6})
Counter({0: 45, 1: 5})
Counter({0: 49, 1: 1})Next, we can stratify the train-test split and compare the results.
# split imbalanced dataset into train and test sets with stratification from collections import Counter from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split # create dataset X, y = make_classification(n_samples=100, weights=[0.94], flip_y=0, random_state=1) print(Counter(y)) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1, stratify=y) print(Counter(y_train)) print(Counter(y_test))
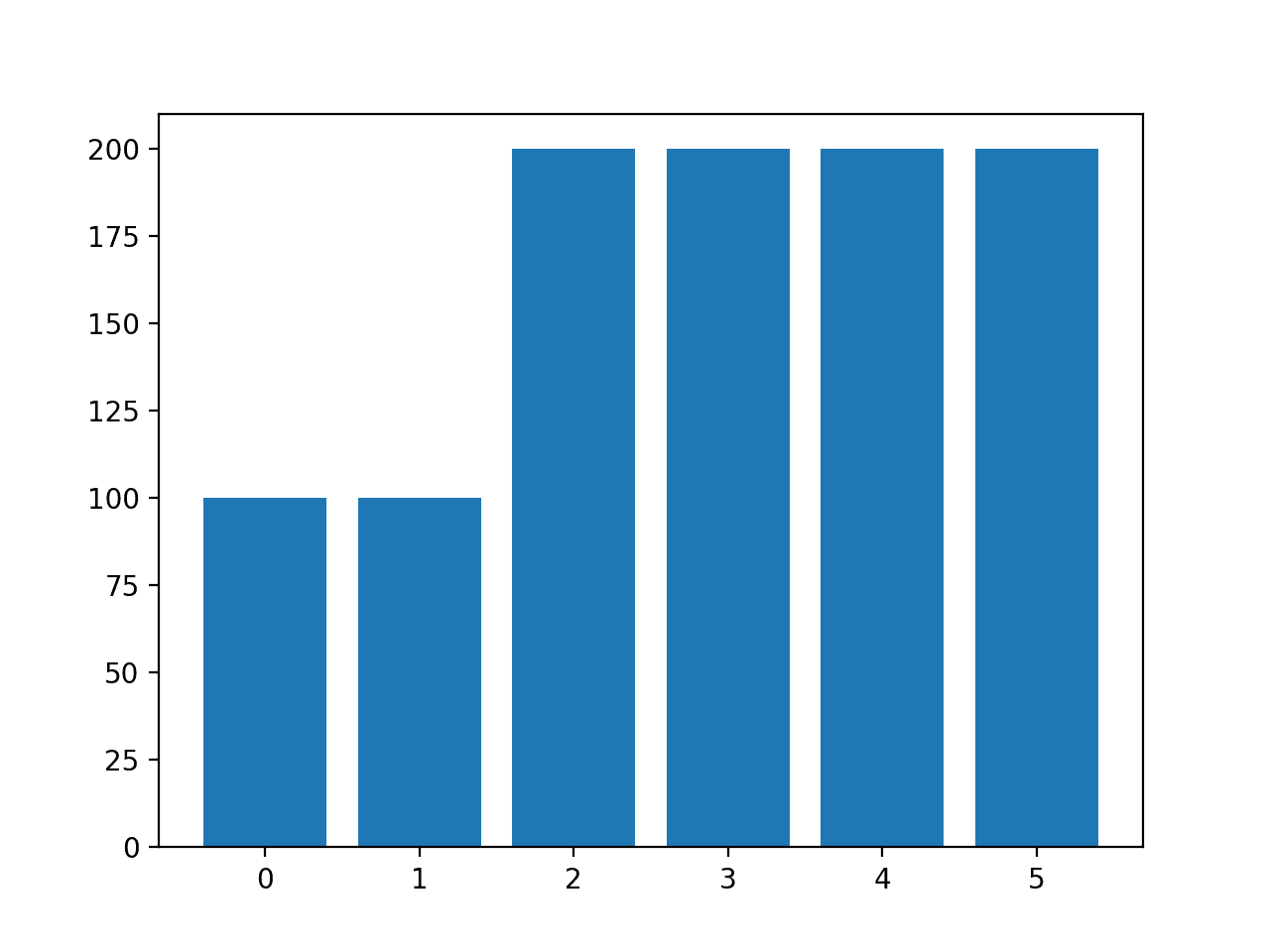
Given that we have used a 50 percent split for the train and test sets, we would expect both the train and test sets to have 47/3 examples in the train/test sets respectively.
Running the example, we can see that in this case, the stratified version of the train-test split has created both the train and test datasets with 47/3 examples in the train/test sets as we expected.
Counter({0: 94, 1: 6})
Counter({0: 47, 1: 3})
Counter({0: 47, 1: 3})Now that we are familiar with the train_test_split() function, let’s look at how we can use it to evaluate a machine learning model.
Train-Test Split to Evaluate Machine Learning Models
In this section, we will explore using the train-test split procedure to evaluate machine learning models on standard classification and regression predictive modeling datasets.
Train-Test Split for Classification
We will demonstrate how to use the train-test split to evaluate a random forest algorithm on the sonar dataset.
The sonar dataset is a standard machine learning dataset composed of 208 rows of data with 60 numerical input variables and a target variable with two class values, e.g. binary classification.
The dataset involves predicting whether sonar returns indicate a rock or simulated mine.
No need to download the dataset; we will download it automatically as part of our worked examples.
The example below downloads the dataset and summarizes its shape.
# summarize the sonar dataset from pandas import read_csv # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape)
Running the example downloads the dataset and splits it into input and output elements. As expected, we can see that there are 208 rows of data with 60 input variables.
(208, 60) (208,)
We can now evaluate a model using a train-test split.
First, the loaded dataset must be split into input and output components.
... # split into inputs and outputs X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape)
Next, we can split the dataset so that 67 percent is used to train the model and 33 percent is used to evaluate it. This split was chosen arbitrarily.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
We can then define and fit the model on the training dataset.
... # fit the model model = RandomForestClassifier(random_state=1) model.fit(X_train, y_train)
Then use the fit model to make predictions and evaluate the predictions using the classification accuracy performance metric.
...
# make predictions
yhat = model.predict(X_test)
# evaluate predictions
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % acc)Tying this together, the complete example is listed below.
# train-test split evaluation random forest on the sonar dataset
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv'
dataframe = read_csv(url, header=None)
data = dataframe.values
# split into inputs and outputs
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
# split into train test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# fit the model
model = RandomForestClassifier(random_state=1)
model.fit(X_train, y_train)
# make predictions
yhat = model.predict(X_test)
# evaluate predictions
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % acc)Running the example first loads the dataset and confirms the number of rows in the input and output elements.
The dataset is split into train and test sets and we can see that there are 139 rows for training and 69 rows for the test set.
Finally, the model is evaluated on the test set and the performance of the model when making predictions on new data has an accuracy of about 78.3 percent.
(208, 60) (208,) (139, 60) (69, 60) (139,) (69,) Accuracy: 0.783
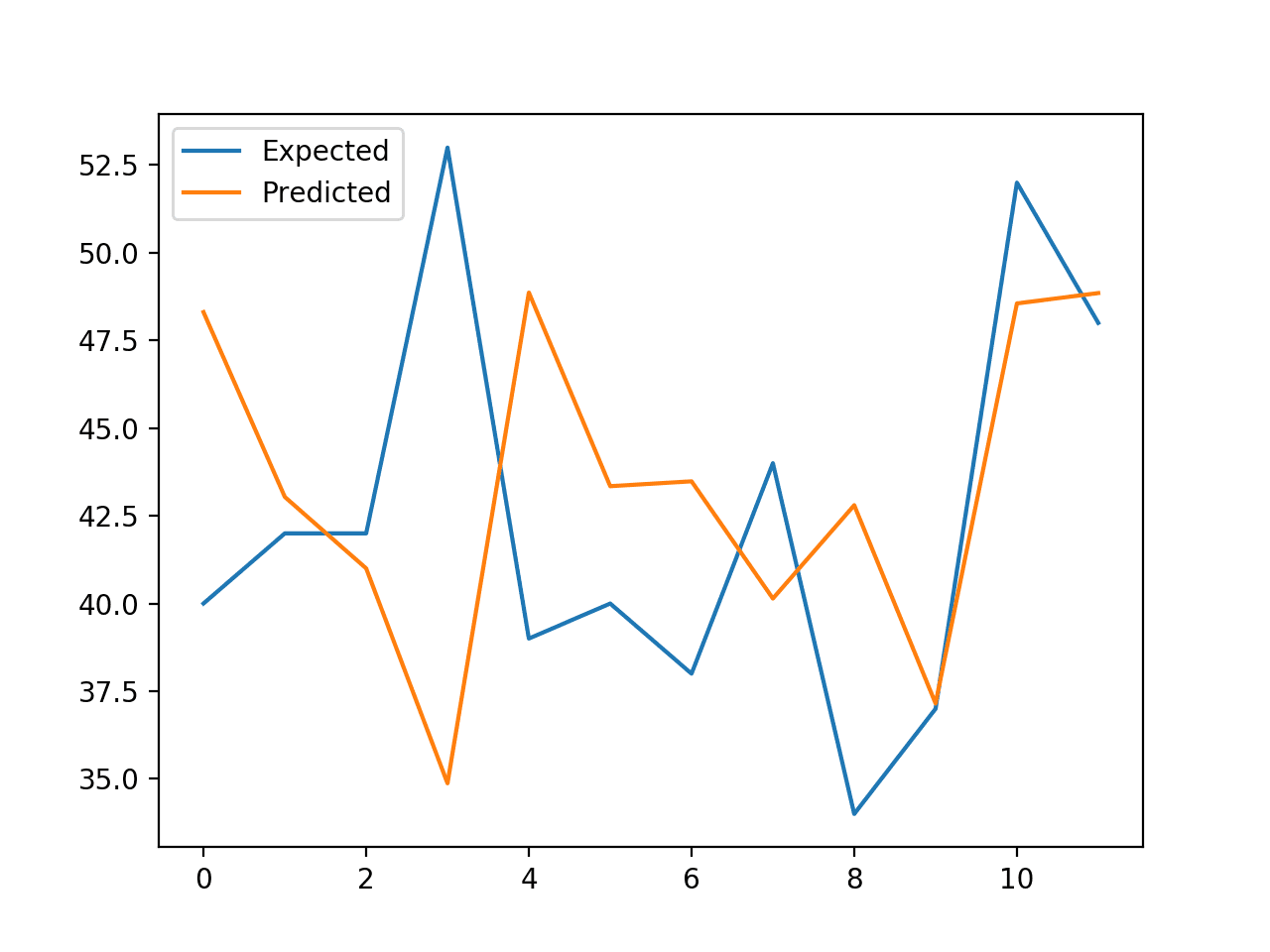
Train-Test Split for Regression
We will demonstrate how to use the train-test split to evaluate a random forest algorithm on the housing dataset.
The housing dataset is a standard machine learning dataset composed of 506 rows of data with 13 numerical input variables and a numerical target variable.
The dataset involves predicting the house price given details of the house’s suburb in the American city of Boston.
No need to download the dataset; we will download it automatically as part of our worked examples.
The example below downloads and loads the dataset as a Pandas DataFrame and summarizes the shape of the dataset.
# load and summarize the housing dataset from pandas import read_csv # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv' dataframe = read_csv(url, header=None) # summarize shape print(dataframe.shape)
Running the example confirms the 506 rows of data and 13 input variables and single numeric target variables (14 in total).
(506, 14)
We can now evaluate a model using a train-test split.
First, the loaded dataset must be split into input and output components.
... # split into inputs and outputs X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape)
Next, we can split the dataset so that 67 percent is used to train the model and 33 percent is used to evaluate it. This split was chosen arbitrarily.
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
We can then define and fit the model on the training dataset.
... # fit the model model = RandomForestRegressor(random_state=1) model.fit(X_train, y_train)
Then use the fit model to make predictions and evaluate the predictions using the mean absolute error (MAE) performance metric.
...
# make predictions
yhat = model.predict(X_test)
# evaluate predictions
mae = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % mae)Tying this together, the complete example is listed below.
# train-test split evaluation random forest on the housing dataset
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv'
dataframe = read_csv(url, header=None)
data = dataframe.values
# split into inputs and outputs
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
# split into train test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# fit the model
model = RandomForestRegressor(random_state=1)
model.fit(X_train, y_train)
# make predictions
yhat = model.predict(X_test)
# evaluate predictions
mae = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % mae)Running the example first loads the dataset and confirms the number of rows in the input and output elements.
The dataset is split into train and test sets and we can see that there are 339 rows for training and 167 rows for the test set.
Finally, the model is evaluated on the test set and the performance of the model when making predictions on new data is a mean absolute error of about 2.211 (thousands of dollars).
(506, 13) (506,) (339, 13) (167, 13) (339,) (167,) MAE: 2.157
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- sklearn.model_selection.train_test_split API.
- sklearn.datasets.make_classification API.
- sklearn.datasets.make_blobs API.
Summary
In this tutorial, you discovered how to evaluate machine learning models using the train-test split.
Specifically, you learned:
- The train-test split procedure is appropriate when you have a very large dataset, a costly model to train, or require a good estimate of model performance quickly.
- How to use the scikit-learn machine learning library to perform the train-test split procedure.
- How to evaluate machine learning algorithms for classification and regression using the train-test split.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Train-Test Split for Evaluating Machine Learning Algorithms appeared first on Machine Learning Mastery.