Blending is an ensemble machine learning algorithm.
It is a colloquial name for stacked generalization or stacking ensemble where instead of fitting the meta-model on out-of-fold predictions made by the base model, it is fit on predictions made on a holdout dataset.
Blending was used to describe stacking models that combined many hundreds of predictive models by competitors in the $1M Netflix machine learning competition, and as such, remains a popular technique and name for stacking in competitive machine learning circles, such as the Kaggle community.
In this tutorial, you will discover how to develop and evaluate a blending ensemble in python.
After completing this tutorial, you will know:
- Blending ensembles are a type of stacking where the meta-model is fit using predictions on a holdout validation dataset instead of out-of-fold predictions.
- How to develop a blending ensemble, including functions for training the model and making predictions on new data.
- How to evaluate blending ensembles for classification and regression predictive modeling problems.
Let’s get started.
![Blending Ensemble Machine Learning With Python]()
Blending Ensemble Machine Learning With Python
Photo by Nathalie, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- Blending Ensemble
- Develop a Blending Ensemble
- Blending Ensemble for Classification
- Blending Ensemble for Regression
Blending Ensemble
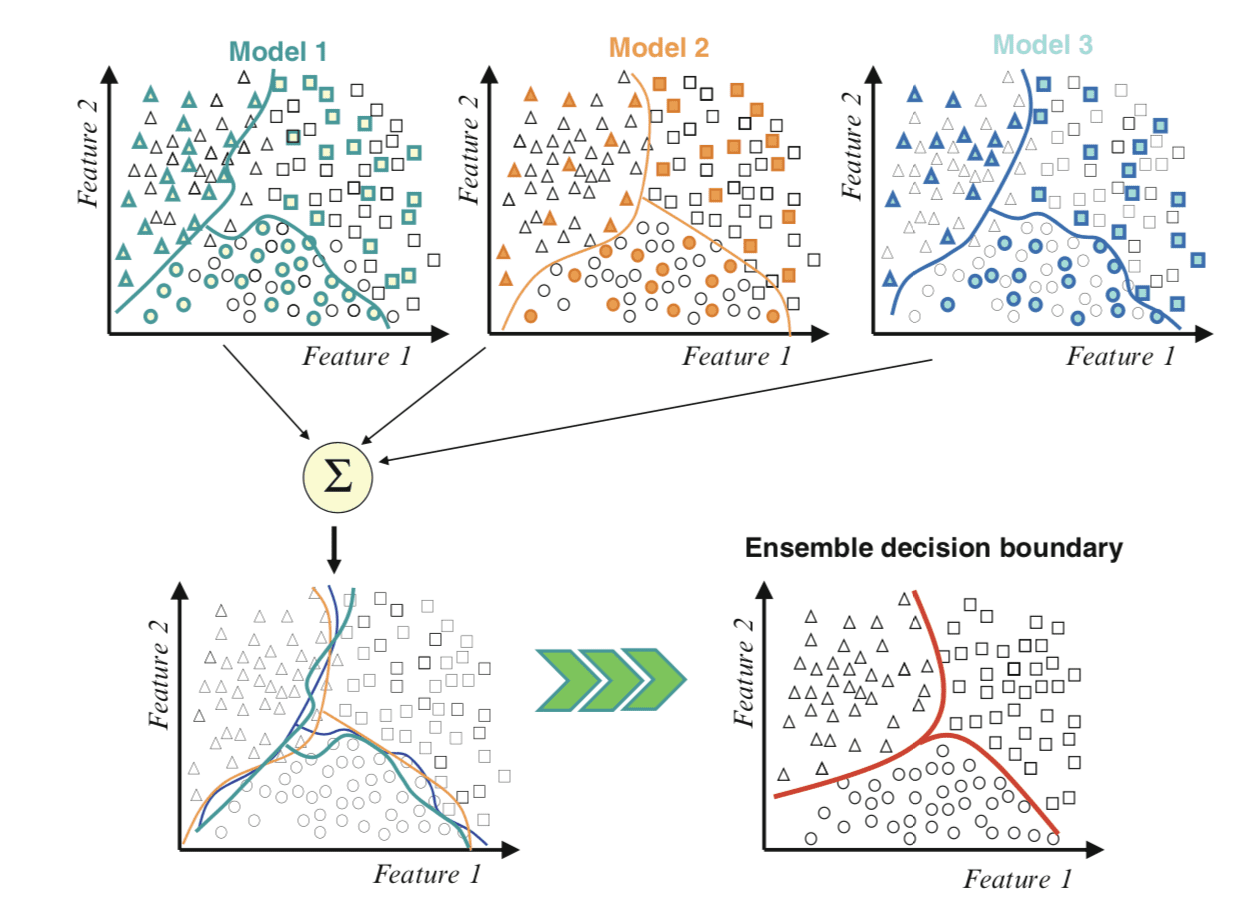
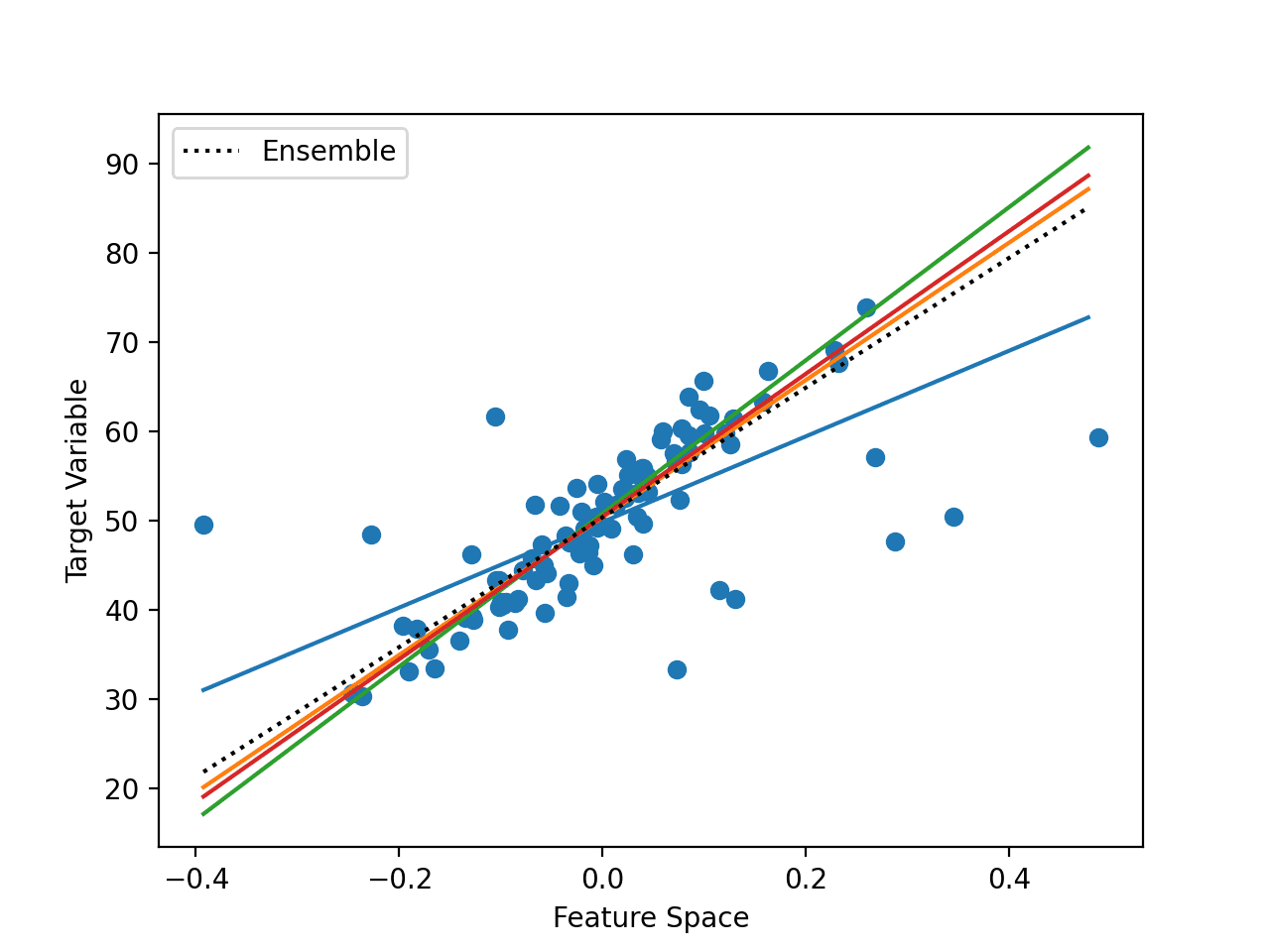
Blending is an ensemble machine learning technique that uses a machine learning model to learn how to best combine the predictions from multiple contributing ensemble member models.
As such, blending is the same as stacked generalization, known as stacking, broadly conceived. Often, blending and stacking are used interchangeably in the same paper or model description.
Many machine learning practitioners have had success using stacking and related techniques to boost prediction accuracy beyond the level obtained by any of the individual models. In some contexts, stacking is also referred to as blending, and we will use the terms interchangeably here.
— Feature-Weighted Linear Stacking, 2009.
The architecture of a stacking model involves two or more base models, often referred to as level-0 models, and a meta-model that combines the predictions of the base models, referred to as a level-1 model. The meta-model is trained on the predictions made by base models on out-of-sample data.
- Level-0 Models (Base-Models): Models fit on the training data and whose predictions are compiled.
- Level-1 Model (Meta-Model): Model that learns how to best combine the predictions of the base models.
Nevertheless, blending has specific connotations for how to construct a stacking ensemble model.
Blending may suggest developing a stacking ensemble where the base-models are machine learning models of any type, and the meta-model is a linear model that “blends” the predictions of the base-models.
For example, a linear regression model when predicting a numerical value or a logistic regression model when predicting a class label would calculate a weighted sum of the predictions made by base models and would be considered a blending of predictions.
- Blending Ensemble: Use of a linear model, such as linear regression or logistic regression, as the meta-model in a stacking ensemble.
Blending was the term commonly used for stacking ensembles during the Netflix prize in 2009. The prize involved teams seeking movie recommendation predictions that performed better than the native Netflix algorithm and a US$1M prize was awarded to the team that achieved a 10 percent performance improvement.
Our RMSE=0.8643^2 solution is a linear blend of over 100 results. […] Throughout the description of the methods, we highlight the specific predictors that participated in the final blended solution.
— The BellKor 2008 Solution to the Netflix Prize, 2008.
As such, blending is a colloquial term for ensemble learning with a stacking-type architecture model. It is rarely, if ever, used in textbooks or academic papers, other than those related to competitive machine learning.
Most commonly, blending is used to describe the specific application of stacking where the meta-model is trained on the predictions made by base-models on a hold-out validation dataset. In this context, stacking is reserved for a meta-model that is trained on out-of fold predictions during a cross-validation procedure.
- Blending: Stacking-type ensemble where the meta-model is trained on predictions made on a holdout dataset.
- Stacking: Stacking-type ensemble where the meta-model is trained on out-of-fold predictions made during k-fold cross-validation.
This distinction is common among the Kaggle competitive machine learning community.
Blending is a word introduced by the Netflix winners. It is very close to stacked generalization, but a bit simpler and less risk of an information leak. […] With blending, instead of creating out-of-fold predictions for the train set, you create a small holdout set of say 10% of the train set. The stacker model then trains on this holdout set only.
— Kaggle Ensemble Guide, MLWave, 2015.
We will use this latter definition of blending.
Next, let’s look at how we can implement blending.
Develop a Blending Ensemble
The scikit-learn library does not natively support blending at the time of writing.
Instead, we can implement it ourselves using scikit-learn models.
First, we need to create a number of base models. These can be any models we like for a regression or classification problem. We can define a function get_models() that returns a list of models where each model is defined as a tuple with a name and the configured classifier or regression object.
For example, for a classification problem, we might use a logistic regression, kNN, decision tree, SVM, and Naive Bayes model.
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
models.append(('bayes', GaussianNB()))
return modelsNext, we need to fit the blending model.
Recall that the base models are fit on a training dataset. The meta-model is fit on the predictions made by each base model on a holdout dataset.
First, we can enumerate the list of models and fit each in turn on the training dataset. Also in this loop, we can use the fit model to make a prediction on the hold out (validation) dataset and store the predictions for later.
...
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict(X_val)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store predictions as input for blending
meta_X.append(yhat)
We now have “meta_X” that represents the input data that can be used to train the meta-model. Each column or feature represents the output of one base model.
Each row represents the one sample from the holdout dataset. We can use the hstack() function to ensure this dataset is a 2D numpy array as expected by a machine learning model.
...
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
We can now train our meta-model. This can be any machine learning model we like, such as logistic regression for classification.
...
# define blending model
blender = LogisticRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
We can tie all of this together into a function named fit_ensemble() that trains the blending model using a training dataset and holdout validation dataset.
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict(X_val)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LogisticRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
The next step is to use the blending ensemble to make predictions on new data.
This is a two-step process. The first step is to use each base model to make a prediction. These predictions are then gathered together and used as input to the blending model to make the final prediction.
We can use the same looping structure as we did when training the model. That is, we can collect the predictions from each base model into a training dataset, stack the predictions together, and call predict() on the blender model with this meta-level dataset.
The predict_ensemble() function below implements this. Given the list of fit base models, the fit blender ensemble, and a dataset (such as a test dataset or new data), it will return a set of predictions for the dataset.
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for name, model in models:
# predict with base model
yhat = model.predict(X_test)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
We now have all of the elements required to implement a blending ensemble for classification or regression predictive modeling problems
Blending Ensemble for Classification
In this section, we will look at using blending for a classification problem.
First, we can use the make_classification() function to create a synthetic binary classification problem with 10,000 examples and 20 input features.
The complete example is listed below.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
Running the example creates the dataset and summarizes the shape of the input and output components.
(10000, 20) (10000,)
Next, we need to split the dataset up, first into train and test sets, and then the training set into a subset used to train the base models and a subset used to train the meta-model.
In this case, we will use a 50-50 split for the train and test sets, then use a 67-33 split for train and validation sets.
...
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# split training set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s, Test: %s' % (X_train.shape, X_val.shape, X_test.shape))We can then use the get_models() function from the previous section to create the classification models used in the ensemble.
The fit_ensemble() function can then be called to fit the blending ensemble on the train and validation datasets and the predict_ensemble() function can be used to make predictions on the holdout dataset.
...
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make predictions on test set
yhat = predict_ensemble(models, blender, X_test)
Finally, we can evaluate the performance of the blending model by reporting the classification accuracy on the test dataset.
...
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('Blending Accuracy: %.3f' % score)Tying this all together, the complete example of evaluating a blending ensemble on the synthetic binary classification problem is listed below.
# blending ensemble for classification using hard voting
from numpy import hstack
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC()))
models.append(('bayes', GaussianNB()))
return models
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict(X_val)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LogisticRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for name, model in models:
# predict with base model
yhat = model.predict(X_test)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
# define dataset
X, y = get_dataset()
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# split training set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s, Test: %s' % (X_train.shape, X_val.shape, X_test.shape))
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make predictions on test set
yhat = predict_ensemble(models, blender, X_test)
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('Blending Accuracy: %.3f' % (score*100))Running the example first reports the shape of the train, validation, and test datasets, then the accuracy of the ensemble on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
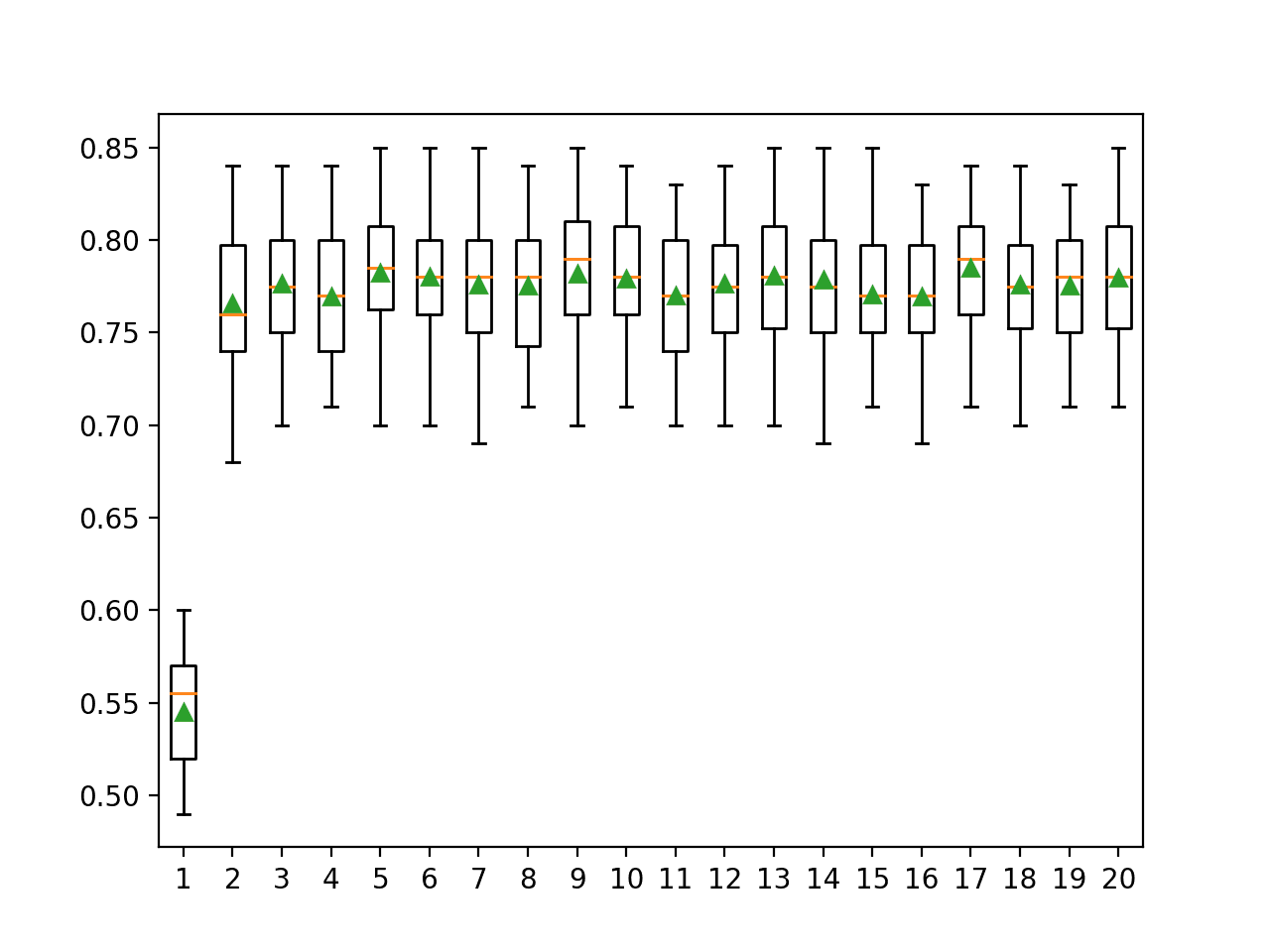
In this case, we can see that the blending ensemble achieved a classification accuracy of about 97.900 percent.
Train: (3350, 20), Val: (1650, 20), Test: (5000, 20)
Blending Accuracy: 97.900
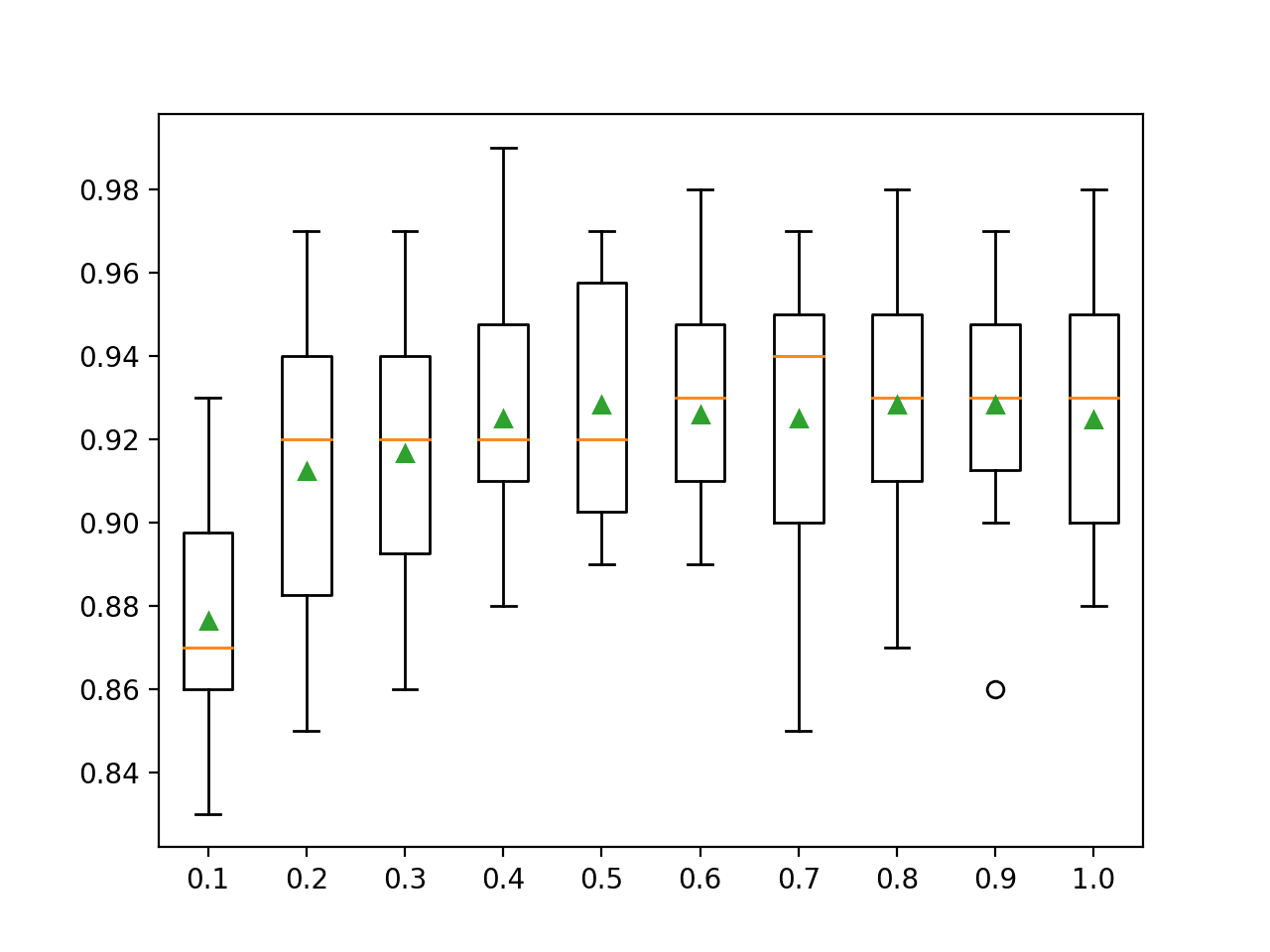
In the previous example, crisp class label predictions were combined using the blending model. This is a type of hard voting.
An alternative is to have each model predict class probabilities and use the meta-model to blend the probabilities. This is a type of soft voting and can result in better performance in some cases.
First, we must configure the models to return probabilities, such as the SVM model.
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
models.append(('bayes', GaussianNB()))
return modelsNext, we must change the base models to predict probabilities instead of crisp class labels.
This can be achieved by calling the predict_proba() function in the fit_ensemble() function when fitting the base models.
...
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict_proba(X_val)
# store predictions as input for blending
meta_X.append(yhat)
This means that the meta dataset used to train the meta-model will have n columns per classifier, where n is the number of classes in the prediction problem, two in our case.
We also need to change the predictions made by the base models when using the blending model to make predictions on new data.
...
# make predictions with base models
meta_X = list()
for name, model in models:
# predict with base model
yhat = model.predict_proba(X_test)
# store prediction
meta_X.append(yhat)
Tying this together, the complete example of using blending on predicted class probabilities for the synthetic binary classification problem is listed below.
# blending ensemble for classification using soft voting
from numpy import hstack
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
models.append(('bayes', GaussianNB()))
return models
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict_proba(X_val)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LogisticRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for name, model in models:
# predict with base model
yhat = model.predict_proba(X_test)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
# define dataset
X, y = get_dataset()
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# split training set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s, Test: %s' % (X_train.shape, X_val.shape, X_test.shape))
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make predictions on test set
yhat = predict_ensemble(models, blender, X_test)
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('Blending Accuracy: %.3f' % (score*100))Running the example first reports the shape of the train, validation, and test datasets, then the accuracy of the ensemble on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
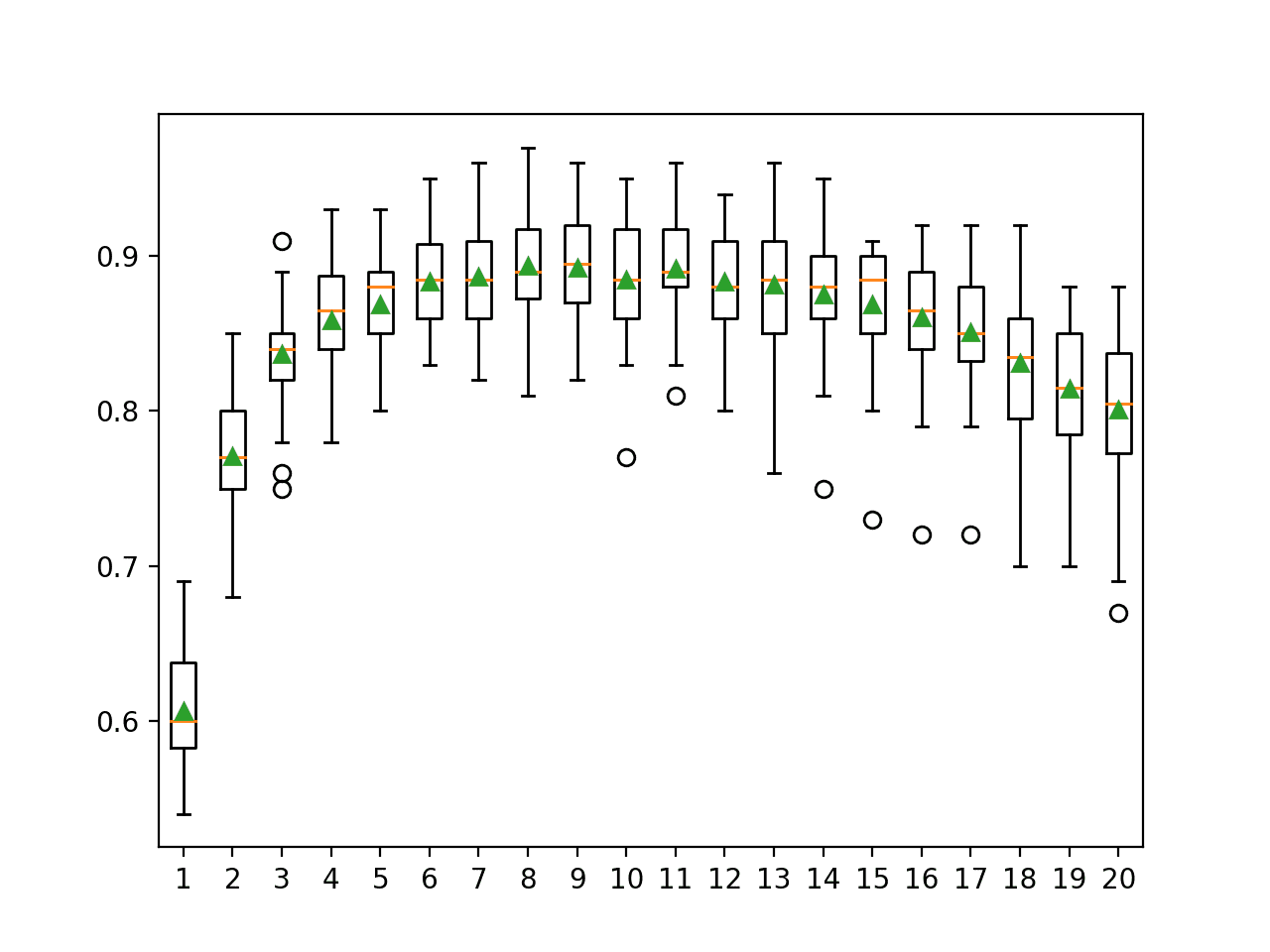
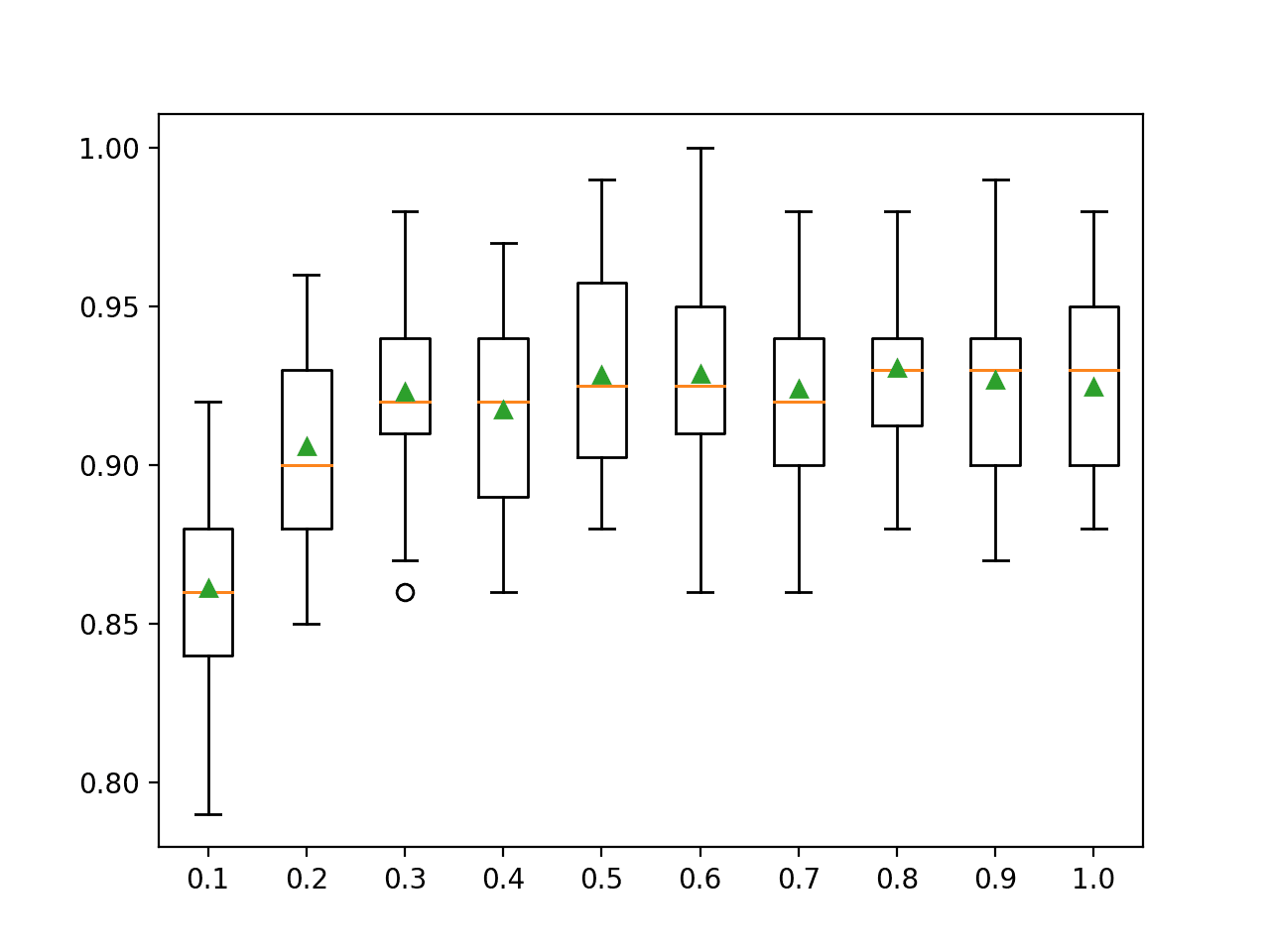
In this case, we can see that blending the class probabilities resulted in a lift in classification accuracy to about 98.240 percent.
Train: (3350, 20), Val: (1650, 20), Test: (5000, 20)
Blending Accuracy: 98.240
A blending ensemble is only effective if it is able to out-perform any single contributing model.
We can confirm this by evaluating each of the base models in isolation. Each base model can be fit on the entire training dataset (unlike the blending ensemble) and evaluated on the test dataset (just like the blending ensemble).
The example below demonstrates this, evaluating each base model in isolation.
# evaluate base models on the entire training dataset
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
models.append(('bayes', GaussianNB()))
return models
# define dataset
X, y = get_dataset()
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# summarize data split
print('Train: %s, Test: %s' % (X_train_full.shape, X_test.shape))
# create the base models
models = get_models()
# evaluate standalone model
for name, model in models:
# fit the model on the training dataset
model.fit(X_train_full, y_train_full)
# make a prediction on the test dataset
yhat = model.predict(X_test)
# evaluate the predictions
score = accuracy_score(y_test, yhat)
# report the score
print('>%s Accuracy: %.3f' % (name, score*100))Running the example first reports the shape of the full train and test datasets, then the accuracy of each base model on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that all models perform worse than the blended ensemble.
Interestingly, we can see that the SVM comes very close to achieving an accuracy of 98.200 percent compared to 98.240 achieved with the blending ensemble.
Train: (5000, 20), Test: (5000, 20)
>lr Accuracy: 87.800
>knn Accuracy: 97.380
>cart Accuracy: 88.200
>svm Accuracy: 98.200
>bayes Accuracy: 87.300
We may choose to use a blending ensemble as our final model.
This involves fitting the ensemble on the entire training dataset and making predictions on new examples. Specifically, the entire training dataset is split onto train and validation sets to train the base and meta-models respectively, then the ensemble can be used to make a prediction.
The complete example of making a prediction on new data with a blending ensemble for classification is listed below.
# example of making a prediction with a blending ensemble for classification
from numpy import hstack
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LogisticRegression()))
models.append(('knn', KNeighborsClassifier()))
models.append(('cart', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
models.append(('bayes', GaussianNB()))
return models
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for _, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict_proba(X_val)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LogisticRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for _, model in models:
# predict with base model
yhat = model.predict_proba(X_test)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
# define dataset
X, y = get_dataset()
# split dataset set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s' % (X_train.shape, X_val.shape))
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make a prediction on a new row of data
row = [-0.30335011, 2.68066314, 2.07794281, 1.15253537, -2.0583897, -2.51936601, 0.67513028, -3.20651939, -1.60345385, 3.68820714, 0.05370913, 1.35804433, 0.42011397, 1.4732839, 2.89997622, 1.61119399, 7.72630965, -2.84089477, -1.83977415, 1.34381989]
yhat = predict_ensemble(models, blender, [row])
# summarize prediction
print('Predicted Class: %d' % (yhat))Running the example fits the blending ensemble model on the dataset and is then used to make a prediction on a new row of data, as we might when using the model in an application.
Train: (6700, 20), Val: (3300, 20)
Predicted Class: 1
Next, let’s explore how we might evaluate a blending ensemble for regression.
Blending Ensemble for Regression
In this section, we will look at using stacking for a regression problem.
First, we can use the make_regression() function to create a synthetic regression problem with 10,000 examples and 20 input features.
The complete example is listed below.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10, noise=0.3, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
Running the example creates the dataset and summarizes the shape of the input and output components.
(10000, 20) (10000,)
Next, we can define the list of regression models to use as base models. In this case, we will use linear regression, kNN, decision tree, and SVM models.
# get a list of base models
def get_models():
models = list()
models.append(('lr', LinearRegression()))
models.append(('knn', KNeighborsRegressor()))
models.append(('cart', DecisionTreeRegressor()))
models.append(('svm', SVR()))
return modelsThe fit_ensemble() function used to train the blending ensemble is unchanged from classification, other than the model used for blending must be changed to a regression model.
We will use the linear regression model in this case.
...
# define blending model
blender = LinearRegression()
Given that it is a regression problem, we will evaluate the performance of the model using an error metric, in this case, the mean absolute error, or MAE for short.
...
# evaluate predictions
score = mean_absolute_error(y_test, yhat)
print('Blending MAE: %.3f' % score)Tying this together, the complete example of a blending ensemble for the synthetic regression predictive modeling problem is listed below.
# evaluate blending ensemble for regression
from numpy import hstack
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
# get the dataset
def get_dataset():
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10, noise=0.3, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LinearRegression()))
models.append(('knn', KNeighborsRegressor()))
models.append(('cart', DecisionTreeRegressor()))
models.append(('svm', SVR()))
return models
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for name, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict(X_val)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LinearRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for name, model in models:
# predict with base model
yhat = model.predict(X_test)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
# define dataset
X, y = get_dataset()
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# split training set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s, Test: %s' % (X_train.shape, X_val.shape, X_test.shape))
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make predictions on test set
yhat = predict_ensemble(models, blender, X_test)
# evaluate predictions
score = mean_absolute_error(y_test, yhat)
print('Blending MAE: %.3f' % score)Running the example first reports the shape of the train, validation, and test datasets, then the MAE of the ensemble on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the blending ensemble achieved a MAE of about 0.237 on the test dataset.
Train: (3350, 20), Val: (1650, 20), Test: (5000, 20)
Blending MAE: 0.237
As with classification, the blending ensemble is only useful if it performs better than any of the base models that contribute to the ensemble.
We can check this by evaluating each base model in isolation by first fitting it on the entire training dataset (unlike the blending ensemble) and making predictions on the test dataset (like the blending ensemble).
The example below evaluates each of the base models in isolation on the synthetic regression predictive modeling dataset.
# evaluate base models in isolation on the regression dataset
from numpy import hstack
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
# get the dataset
def get_dataset():
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10, noise=0.3, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LinearRegression()))
models.append(('knn', KNeighborsRegressor()))
models.append(('cart', DecisionTreeRegressor()))
models.append(('svm', SVR()))
return models
# define dataset
X, y = get_dataset()
# split dataset into train and test sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# summarize data split
print('Train: %s, Test: %s' % (X_train_full.shape, X_test.shape))
# create the base models
models = get_models()
# evaluate standalone model
for name, model in models:
# fit the model on the training dataset
model.fit(X_train_full, y_train_full)
# make a prediction on the test dataset
yhat = model.predict(X_test)
# evaluate the predictions
score = mean_absolute_error(y_test, yhat)
# report the score
print('>%s MAE: %.3f' % (name, score))Running the example first reports the shape of the full train and test datasets, then the MAE of each base model on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that indeed the linear regression model has performed slightly better than the blending ensemble, achieving a MAE of 0.236 as compared to 0.237 with the ensemble. This may be because of the way that the synthetic dataset was constructed.
Nevertheless, in this case, we would choose to use the linear regression model directly on this problem. This highlights the importance of checking the performance of the contributing models before adopting an ensemble model as the final model.
Train: (5000, 20), Test: (5000, 20)
>lr MAE: 0.236
>knn MAE: 100.169
>cart MAE: 133.744
>svm MAE: 138.195
Again, we may choose to use a blending ensemble as our final model for regression.
This involves fitting splitting the entire dataset into train and validation sets to fit the base and meta-models respectively, then the ensemble can be used to make a prediction for a new row of data.
The complete example of making a prediction on new data with a blending ensemble for regression is listed below.
# example of making a prediction with a blending ensemble for regression
from numpy import hstack
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
# get the dataset
def get_dataset():
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10, noise=0.3, random_state=7)
return X, y
# get a list of base models
def get_models():
models = list()
models.append(('lr', LinearRegression()))
models.append(('knn', KNeighborsRegressor()))
models.append(('cart', DecisionTreeRegressor()))
models.append(('svm', SVR()))
return models
# fit the blending ensemble
def fit_ensemble(models, X_train, X_val, y_train, y_val):
# fit all models on the training set and predict on hold out set
meta_X = list()
for _, model in models:
# fit in training set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict(X_val)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store predictions as input for blending
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# define blending model
blender = LinearRegression()
# fit on predictions from base models
blender.fit(meta_X, y_val)
return blender
# make a prediction with the blending ensemble
def predict_ensemble(models, blender, X_test):
# make predictions with base models
meta_X = list()
for _, model in models:
# predict with base model
yhat = model.predict(X_test)
# reshape predictions into a matrix with one column
yhat = yhat.reshape(len(yhat), 1)
# store prediction
meta_X.append(yhat)
# create 2d array from predictions, each set is an input feature
meta_X = hstack(meta_X)
# predict
return blender.predict(meta_X)
# define dataset
X, y = get_dataset()
# split dataset set into train and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.33, random_state=1)
# summarize data split
print('Train: %s, Val: %s' % (X_train.shape, X_val.shape))
# create the base models
models = get_models()
# train the blending ensemble
blender = fit_ensemble(models, X_train, X_val, y_train, y_val)
# make a prediction on a new row of data
row = [-0.24038754, 0.55423865, -0.48979221, 1.56074459, -1.16007611, 1.10049103, 1.18385406, -1.57344162, 0.97862519, -0.03166643, 1.77099821, 1.98645499, 0.86780193, 2.01534177, 2.51509494, -1.04609004, -0.19428148, -0.05967386, -2.67168985, 1.07182911]
yhat = predict_ensemble(models, blender, [row])
# summarize prediction
print('Predicted: %.3f' % (yhat[0]))Running the example fits the blending ensemble model on the dataset and is then used to make a prediction on a new row of data, as we might when using the model in an application.
Train: (6700, 20), Val: (3300, 20)
Predicted: 359.986
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Related Tutorials
Papers
Articles
Summary
In this tutorial, you discovered how to develop and evaluate a blending ensemble in python.
Specifically, you learned:
- Blending ensembles are a type of stacking where the meta-model is fit using predictions on a holdout validation dataset instead of out-of-fold predictions.
- How to develop a blending ensemble, including functions for training the model and making predictions on new data.
- How to evaluate blending ensembles for classification and regression predictive modeling problems.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Blending Ensemble Machine Learning With Python appeared first on Machine Learning Mastery.